Falls Sie die technischen Aspekte unserer Arbeit interessieren (falls nicht, bitte zurück zur Hauptseite), hier ein Einblick in das verwendete Software-"Ökosystem":
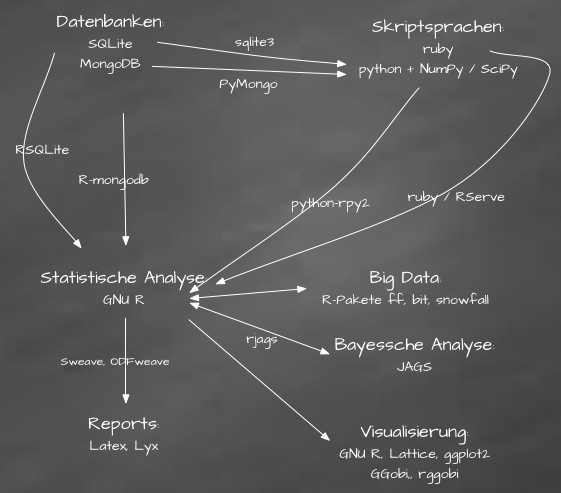
Bei größeren Datenmengen ist es sinnvoll, die Daten in Form einer wohlstrukturierten Datenbank vorzuhalten. Je nach Art der Daten kommen verschiedene Datenbanktypen in Frage:
- eine klassische SQL-Datenbank (wir bevorzugen die sehr schnelle SQLite-Datenbank, die auch einfach zu administrieren ist),
- eine spaltenorientierte Datenbank (z.B. HBase) oder
- eine dokumentenorientierte Datenbank (unser Favorit ist mongoDB).
Alle genannten Datenbanken lassen sich mit modernen Skriptsprachen steuern: unsere Favoriten sind python (wegen der sehr guten numerischen Bibliotheken) und ruby (die eleganteste, objekt-orientierte Sprache, die wir kennen).
Für die skriptgesteuerte Zusammenführung verschiedener Datenquellen (data merging und record linking), Datenbereinigung (data cleaning), Datenfilterung und Datenselektion sind beide genannten Skriptsprachen hervorragend geeignet.
Für statistische Analysen verwenden wir hauptsächlich GNU R, der Open-Source-Nachfolger von S und S-Plus, die ebenso wie UNIX und C in den Bell-Laboratorien entwickelt wurden. GNU R ist kein abgeschlossenes Statistik-Paket, sondern eine Programmiersprache für Statistik, inzwischen die lingua franca der Statistik mit mehreren Tausenden Modulen ("Packages") für die unterschiedlichsten Anwendungszwecke. GNU R läßt sich sowohl von python (mittels rpy2) als auch von ruby (mittels RServe) sehr gut steuern, so daß sich ein kohärentes System zur Datenanalyse ergibt, bestehend aus Datenbank, Skriptsprache und statistischem Analysesystem.
Für die Analyse Bayesscher hierarchischer Modelle (mittels MCMC-Simulation) bietet sich JAGS an; das R-Paket rjags ist ein Interface von R zu JAGS. Daneben gibt es eine Vielfalt weiterer Pakete für spezifische Bayessche Methoden und Modelle.
GNU R hält seine Daten in einer spaltenorientierten Datenbank, die komplett im RAM gehalten werden muß. Diese Beschränkung läßt sich teilweise dadurch umgehen, daß aus der Datenbank nur jeweils die Daten geladen werden, die für die aktuelle Analyse benötigt werden. Reicht dies nicht aus, kann auf Pakete zurückgegriffen werden, die Teilmengen der Daten auf die Festplatte auslagern (z.B. ff, bigmemory, HadoopStreaming) und es können entsprechend angepasste Algorithmen (biglm, biglars, speedglm) verwendet werden.
Zur Visualisierung von Daten und Analyseergebnissen bietet GNU R vielfältige Möglichkeiten: z.B. ermöglichen die Pakete grid, lattice, ggplot2 und vcd die Erstellung von Grafiken für uni- und multivariate Daten, für kontinuierliche und kategoriale Daten, für Partitionsbäume, von kleinteiliger bottom-up-Konstruktion bis zu abstrakteren top-down-Darstellungen. Für die interaktive, visuelle Exploration multivariater Daten ist GGobi sehr hilfreich.
Zur Reportgenerierung bietet LaTeX vielfältige Hilfen, z.B. können mit longtable Tabellen gesetzt werden, deren Zeilen und/oder Spalten mehrere Druckseiten benötigen; die Pakete PSTricks und Xy-pic ermöglichen die Erstellung individualisierter Abbildungen. Graphviz-Graphen können leicht in LaTeX-Dokumente eingebettet werden.
LyX ist eine angenehme Nutzeroberfläche zur schnellen Texteingabe für LaTeX.
Sweave verbindet GNU R und LaTeX/LyX: der R-Code für eine statistische Analyse kann komplett in LaTeX-Dokumente eingebettet werden, so daß alle Komponenten eines Reports (Text, Analysen, Tabellen und Abbildungen) automatisch auf dem aktuellen Stand gehalten werden und der Analyseprozess automatisch dokumentiert ist.
Es ist erstaunlich, wie gut unterschiedliche Open-Source-Komponenten zu einer sehr mächtigen Software-Umgebung für die Datenanalyse zusammengebunden werden können!
